


picture credit: http://www.tecmaths.com
CF-Abacus team: Jean-Sebastien Delfino (IBM), Saravanakumar Srinivasan “Assk” (Independent), Benjamin Cheng (IBM), Hristo Lliev (SAP), Georgi Sabev (SAP), Kevin Yudhiswara (IBM), Piotr Przybylski (IBM), and Rajkiran Balasubramanian (IBM)
Introduction
In part 1 and part 2 of this series we introduced the metering problem that CF-Abacus solves as well as giving a complete overview of its architecture and design. In the last part we discuss the decisions the team took to realize the architecture and give some hints about future directions and conclude with the next steps. We also provide various references that all parties interested with CF-Abacus can use to become more active in the project.
Implementation
To realize the architecture and design goals, the team chose to use Node.js as their primary implementation language and application server. This choice makes sense when one considers that Node.js has excellent built-in libraries for creating Web APIs and first class connectors to CouchDB-like databases.
![]()

Since Node.js is also supported as a first class language in Cloud Foundry, with an active build pack release updates that matches the Node community schedules, this choice is as good as any other language choices for implementation.
The resulting implementation is all contained in the CF-Abacus Github project with each of the six stages for the pipeline modularize into their own Node.js module (applications) each exposing their APIs and connecting to the database layer (CouchDB compliant). Using the cloc tool, we can see that the current code base stands at ~30 KLOC of JavaScript. The complete project stats are: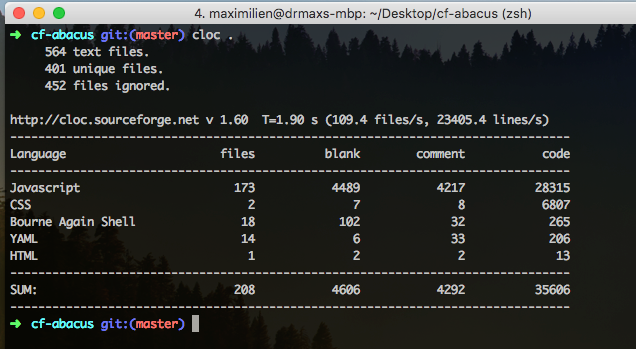
Each pipeline module can be pushed as an app into CF and thus independently managed and scaled like other CF apps. The following steps allow you to try out CF-Abacus quickly by running all micro services on your local machine in memory—this uses an in-memory version of CouchDB called PouchDB.

Once the micro services are running you can then run the tests with: $npm test to see the flow of some usage submissions with a final report. You can see the different services running on your local machine by executing: $ps -A | grep abacus.
Finally, it’s worth noting again that while the demo tries to give you a quick way to verify that CF-Abacus is running and allows you to do some quick tests, a real deployment with a full CouchDB or other compatible DB is needed. In the case of IBM Bluemix, we can happily report that using CF-Abacus we are able to meter data for our more than 1M users and the resulting database working set is in the order of 100s GB and with similar sized shards over the past year.
Future Directions
While the current CF-Abacus implementation has come a long way to provide a scalable, reliable, and modular metering pipeline for any Cloud Foundry installation, it’s not without some shortcomings. Three primary areas of improvements are immediately identifiable:
- User friendliness. A big part of the Abacus configuration and setup is enabling the service providers to plug in their usage data into the pipeline. This on-boarding process has typically been manual with configuration files exchanged via emails to administrators. In order to better scale the number of service providers submitting usages to any Abacus-enabled CF installations, there is clearly a need to have some level of self-onboarding mechanism for service providers. Additionally, the current reporting API is primarily just REST. A user interface that displays typical reporting information would allow first time users of Abacus to be inspired and use it as a starting point for their own user interfaces.
- Pluggable data layer. Any metering pipeline has to process a constant flow of information. The resulting accumulated data, even for a small CF environment can be enormous and hard to deal with, especially over time. The database layer needs to be therefore managed for scale and resiliency. By allowing the database layer to be pluggable and managed via BOSH releases, we can hopefully achieve a system that scales but also be deployed along side the CF installation. The team is currently working on adding MongoDB support as well as a BOSH release for CouchDB itself.
- Error correction. Most aspects of any usage data needs to be accurate in order to be processable. What we mean is that any errors in IDs (e.g., organization, application, service) will result in the usage information not being counted or accumulated or metered. Since the Abacus system is designed to be scalable and support heterogenous providers, such erroneous usage information are more common in real deployments of Abacus. As such, a process to identify, select, and correct usage data that are in error is needed for the system as a whole.
The team is currently working on solutions to the three problem areas and fixing many of the limitations identified above.
Conclusion
As we venture into making Cloud Foundry the default open operating system for the cloud, usage information that can help deployers of CF better bill and manage the usage of their installations’ resources is becoming more and more important. The CF-Abacus project is a solution to providing an open metering engine for any CF environment. The engine was created with a micro-services architecture designed as a pipeline of six stages. Each of the pipeline’s stage can be deployed and scaled as a CF application and each also exposes its own APIs and talks to its own slice of the database. Since we extracted the core CF-Abacus project from IBM’s Bluemix deployment of CloudFoundry we have created a small but active team around the project. With contributors from SAP we were able to add and work on new features such as self-on-boarding as well as expand the realizable DBs that can be used for a real deployment of Abacus. Additionally, we are working to also make Abacus more user friendly and reliable by giving easy means for correcting erroneous usage data and displaying reports.
Join the CF-Abacus team by “kicking the tires” from our Github project page and joining the discussion on our Gitter.im cf-abacus channel.
References
- CF-Abacus Github project
- CF-Abacus introduction presentation
- CF-Abacus Tracker
- CF-Abacus docs: README, FAQs, and API design information
- CF-Abacus Slack and Gitter channels



