

Why is OverlayFS Slow Now?
TL;DR:
Spoiler alert, it isn’t!!
But various changes in how the kernel triggers writeback of dirty inodes introduced between v4.4 and v4.15 led to a marked decrease in performance when it came to handling our Overlay mounted container root filesystems.
Fortunately, because of luck or magic, we may have already solved* the problem long before we knew we had it.
*got around
———————————-
The Full Story
So, one day towards the end of September, we looked up at our team CI/Performance monitor and saw this:
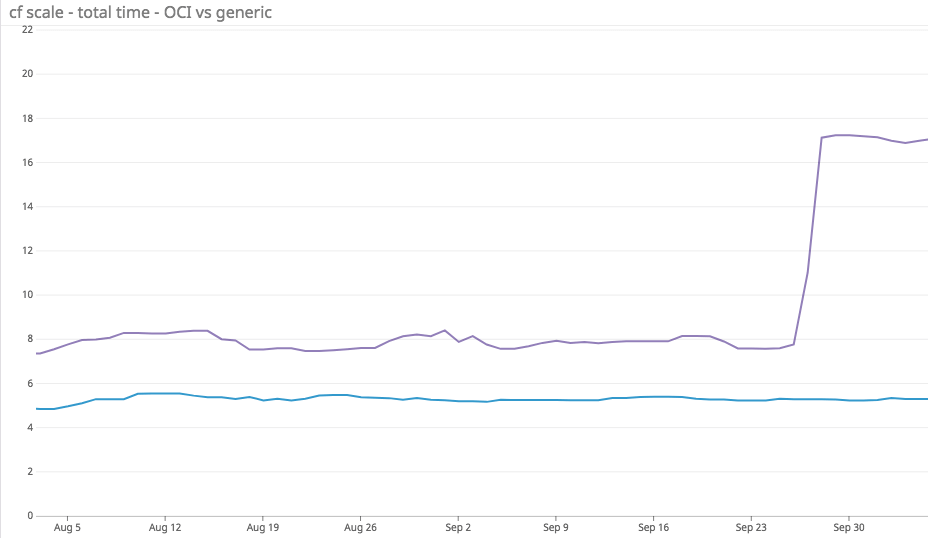
I bet that, despite having limited context and perhaps not even knowing what my team does, you looked at that graph and thought “oh damn”. The reason you thought this is because everyone knows that sudden changes in graphs either mean something very good just happened or something very not good just happened.
This was the second thing.
I’ll go back a bit. My team provides the container runtime for Cloud Foundry. What this boils down to is: when application developers push their code to the cloud, after various things go through various components, we will ensure that app code is booted inside a secure and isolated environment. And we will ensure that it is booted quickly. Speed is, after all, one of the many reasons we love and use containers for this sort of thing.
That is what this graph is showing. Ignore the blue line (the bottom one) for now, I will come back to it later because it is important, but until then just focus on the purple one — the one showing how suddenly Not Fast we are at booting peoples’ apps for them.
Naturally, the first thing we did was find out what had changed in our various repos. A quick git log revealed… my name.
But I hadn’t actually done anything to our code. What that commit did was change the default environment our components run on.
In the last year, all Cloud Foundry components have been moving from Ubuntu Trusty 14.04 based VMs, to Ubuntu Xenial 16.04 ones. Our team has been testing against both for a while to ensure compatibility, with a heavy preference for Xenial since that would soon be the only option. I just happened to notice on that fateful day that the VMs we were using to get the data for that particular graph were provisioned with Trusty, so I thought it sensible to switch them over.
This turned out to be a good idea: it would have been very embarrassing to have gotten all the way to prod (at this time not yet on Xenial) without noticing such a dramatic performance regression.
So what is this graph actually showing? It is not showing an individual application create nor is it showing just the container components. It is measuring the application developer’s whole experience of scaling an already running application from 1 to 10 instances.
The abridged sequence of events is as follows:
– The asynchronous scale request from the app developer (via CLI) goes through various components until the relevant bits end up with the scheduler
– Garden-Runc (that’s us!) is asked to create 9 new containers
– Garden-Runc creates those containers
– The application code is streamed into the containers
– Garden-Runc is asked to create a sidecar container for each container
– Garden-Runc creates those sidecar containers
– Code is streamed into the sidecar containers (this code runs a healthcheck to see whether the application has booted successfully)
– When all of those sidecar processes exit successfully, the app is reported back to the CLI as healthy
– The application developer sees they have 10 running instances and is happy
It is the time taken for all of this which is plotted in that graph.
With so much happening over which we have no control, it was very possible that the slowdown was not down to us at all. But knowing our luck and our track record with major environmental shifts, we knew — it was always going to be us.
1: Logs
Obviously we started with our logs. Garden-Runc components log a lot, so we started by pushing an app to our environment, grepping all mentions of that handle in garden.stdout.log, and having a good ol’ read. And what we saw was:
{"timestamp":"2018-10-24T11:39:55.231873213Z","message":"guardian.run.create-pea.clean-pea.image-plugin-destroy.grootfs.delete.groot-deleting.deleting-image.overlayxfs-destroying-image.starting","data":{"handle":"2d8f7e6d-66fa-4e5d-5cc1-da07-readiness-healthcheck-0"}}
{"timestamp":"2018-10-24T11:40:03.189979808Z","message":"guardian.run.create-pea.clean-pea.image-plugin-destroy.grootfs.delete.groot-deleting.deleting-image.overlayxfs-destroying-image.ending","data":{"handle":"2d8f7e6d-66fa-4e5d-5cc1-da07-readiness-healthcheck-0"}}Why are we deleting an image? What is an image? What is a grootfs? What is a “pea”? Why does it need cleaning? Aren’t we meant to be creating things here?
There is a lot of info in these logs (even though I have edited them for you), so let’s break them down.
Guardian and GrootFS are components of Garden-Runc. Guardian is our container creator. It prepares an OCI compliant container spec, and then passes that to runc, an open source container runtime, which creates and runs a container based on that spec. Before Guardian calls runc, it asks GrootFS (an image plugin) to create a root filesystem for the container. GrootFS imports the filesystem layers and uses OverlayFS to combine them and provide a read-write mountpoint which acts as the container’s rootfs. The path to this rootfs is included in the spec which Guardian passes to runc so that runc can pivot_root to the right place.
(For more on container root filesystems, see Container Root Filesystems in Production.)
A Pea is our name for a sidecar container. (Kubernetes groups its sidecars into a Pod, as in a pod of (Docker) whales. We are Garden so our sidecars are peas… in a pod. Yes, it is hilarious.) Sidecar containers are associated with “full” containers and share some of the resources and configuration of their parent, but can be limited in a different way. Crucially, in the context of our problem, they have their own root filesystem.
In the case of the logs above, the sidecar (pea) was created to run a process which checks whether the primary application container has booted successfully. When the process detects that the app is up and running, it exits, which triggers the teardown of its resources, including the rootfs.
So that is what we are seeing here: for whatever reason we have yet to discover, after a pea has determined that our developer’s app is running and goes into teardown, GrootFS is taking ~8s to delete its root filesystem.
Given that this slowness appeared right after I bumped our VMs’ OS, which we know included a jump from a 4.4 kernel to a 4.15 kernel, I was immediately Very Suspicious that we were apparently losing time in a rootfs deletion.
But there is more to a GrootFS rootfs (sigh, naming) delete than an unmount syscall, so we needed a little more evidence before wading into a kernel bisection.
2: More Logs
So we added even more log lines to GrootFS and pushed another app.
{"timestamp":"2018-10-25T13:12:25.314306368Z","message":"...deleting-image.overlayxfs-destroying-image.starting","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:25.331496182Z","message":"...deleting-image.overlayxfs-destroying-image.getting-project-quota-id","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:25.333481923Z","message":"...deleting-image.overlayxfs-destroying-image.project-id-acquired","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:25.335395181Z","message":"...deleting-image.overlayxfs-destroying-image.unmounting-image","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:32.528611226Z","message":"...deleting-image.overlayxfs-destroying-image.image-unmounted","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:32.529112053Z","message":"...deleting-image.overlayxfs-destroying-image.removing-image-dir","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:32.549213494Z","message":"...deleting-image.overlayxfs-destroying-image.image-dir-deleted","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}
{"timestamp":"2018-10-25T13:12:32.550306115Z","message":"...deleting-image.overlayxfs-destroying-image.ending","data":{"handle":"6a0aed04-fe8e-47a2-5d0b-dfbfc165534f-readiness-healthcheck-0"}}The code between those two log lines was doing a syscall.Unmount and nothing more.
Now that this was looking more like a kernel thing and not a Garden/Cloud Foundry thing, we needed to tighten our reproduction loop.
3: Reliable Reproduction
At the Garden level, and certainly at the GrootFS level, there is no knowledge of an “application”. To Garden, a scaled application is the same as an initial application: all it sees is containers. Peas (sidecars) are handled a little differently by Guardian and therefore follow their own code divergence, but to Runc (the thing handling the creation) a Sidecar container is just another container. Garden may think it has created 10 containers with 10 sidecars, but Runc knows it has simply created 20 containers.
Going further, what does GrootFS know? GrootFS has the least awareness of anything application-y. It just simply, on request, creates a mounted directory which can be used as a root filesystem for a container.
Given that a syscall in heart of GrootFS has the most incidental and tenuous connection to a Cloud Foundry application, we were able cut out a great many extraneous parts and just use a small bash script to mimic an application scale at the filesystem level:
– serially create 10 overlay mounts*
– unmount all mounts simultaneously
… and time each unmount, hopefully seeing some unreasonable slowness.
But it showed nothing. Unmounts went through in under a second. Were we wrong?
Combing through the logs, we remembered that, of course, a container rootfs wouldn’t just be mounted and then unmounted: code would be streamed in. We amended our script to include writing a file (approximately the size of the app we used earlier) into the mountpoint.
And this time we got what we were after: each unmount took up to 10 seconds to complete.
The problem presenting only when data had been written to the mount backed up our theory that this was kernel related, specifically the overlay filesystem, which has been built into the mainline since version 3.18. Given that an overlay filesystem can have up to 3 different inodes for any given file (one at the mount, one in the lower layer and one in the upper layer if the file has been written to), we hypothesised that perhaps something in the way inodes were allocated in overlay had changed between 4.4 and 4.15.
To prove this, we would have to use our script to determine which kernel first saw this problem.
*Application scales would result in parallel container create calls, which technically can mean that rootfs mounts are also done in parallel. However, since the unmount behaviour is the same regardless of whether the mounting is done simultaneously or not, I decided to stick to serial mounts to avoid unnecessary complexity around timing in the repro script.
4: Narrowing It Down…
We were not quite at the point where we needed to do a proper kernel bisect. Fortunately there are a lot of pre-compiled versions available online, so we were able to jump between those in what I like to call a lazy bisect.
As we were fine on 4.4 and not fine on 4.15, we picked a version sort-of in the middle to start: 4.10.
Switching out a kernel is a fairly straightforward thing. Canonical puts all the debs online, so once we downloaded those, we could simply install, update grub, reboot and wait. After a little time we were able to ssh back on and run our reproduction script.
Unmounts went through in a flash, so we moved on to 4.13 (sort-of in between 4.10 and 4.15), ditto. The last minor version was 4.14 which again showed no sign of slow unmounts.
Given that we knew the problem existed in 4.15, we were clearly looking for a patch rather than a minor version.
The patch versions in 4.14 run from 1 to 78, so we again started somewhere vaguely in the middle: 4.14.39. Nothing there. 4.14.58? Nope.
Then we tried 4.14.68.
Finally we got what we were after: slow unmounts.
4.14.63 was also slow, and so was 4.14.60. Our last pre-compiled run was 4.14.59, which showed no performance regression, so now we knew that we were looking for something which went into 4.14.60.
5: Mainline Crack
We were now out of pre-compiled kernel debs so we needed to roll our own.
The first step was to clone down the ubuntu mainline kernel repository (if you plan on trying this at home, be warned: cloning takes ages because the repo is mega). When it finally downloaded, we looked at the git log to see which commits went into our problem version. Normally when bisecting something, you would start with a commit in the middle and then work your way up or down until you get to the culprit.
But since simply switching between pre-compiled versions was slow, I hoped we could cheat a bit to get around compiling that much. So we read the messages of the commits which went into 4.14.60 to look for likely candidates which did things to anything filesystem-y, fs/overlay especially.
One message jumped out at us immediately: ovl: Sync upper dirty data when syncing overlayfs.
The rest of the message also looked good:
When executing filesystem sync or umount on overlayfs,
dirty data does not get synced as expected on upper filesystem.
This patch fixes sync filesystem method to keep data consistency
for overlayfs.
So we decided to focus on this commit first, and go to a regular old bisect from there if it didn’t work out.
We created two custom kernels, one at that commit, and one at the commit before. We tested against the suspect commit first, because that was just the sensible thing to do. The unmounts were slow, and it felt like we might get away with it, but we did our best not to get excited. We switched to the commit before, rebooted, and ran our tests.
And all ten overlay unmounts went through in under a second.
Woohoo! Our gamble paid off, which is a relief because while it took you perhaps a minute to read the last two sections, that whole nonsense took us a week.
6: sync_filesystem
So what happened in that commit which went into kernel version 4.14.60?
Let’s take a look at the diff:
--- a/fs/overlayfs/super.c
+++ b/fs/overlayfs/super.c
@@ -232,6 +232,7 @@ static void ovl_put_super(struct super_b
kfree(ufs);
}
+/* Sync real dirty inodes in upper filesystem (if it exists) */
static int ovl_sync_fs(struct super_block *sb, int wait)
{
struct ovl_fs *ufs = sb->s_fs_info;
@@ -240,14 +241,24 @@ static int ovl_sync_fs(struct super_bloc
if (!ufs->upper_mnt)
return 0;
- upper_sb = ufs->upper_mnt->mnt_sb;
- if (!upper_sb->s_op->sync_fs)
+
+ /*
+ * If this is a sync(2) call or an emergency sync, all the super blocks
+ * will be iterated, including upper_sb, so no need to do anything.
+ *
+ * If this is a syncfs(2) call, then we do need to call
+ * sync_filesystem() on upper_sb, but enough if we do it when being
+ * called with wait == 1.
+ */
+ if (!wait)
return 0;
- /* real inodes have already been synced by sync_filesystem(ovl_sb) */
+ upper_sb = ufs->upper_mnt->mnt_sb;
+
down_read(&upper_sb->s_umount);
- ret = upper_sb->s_op->sync_fs(upper_sb, wait);
+ ret = sync_filesystem(upper_sb);
up_read(&upper_sb->s_umount);
+
return ret;
}
The key thing we care about here is this new line which is treating that upper superblock differently: ret = sync_filesystem(upper_sb);. What is sync_filesystem doing? A fair amount, and I’m not gonna paste the code in; you can check it out here, but we are going to look at a choice comment:
/*
* Write out and wait upon all dirty data associated with this
* superblock. Filesystem data as well as the underlying block
* device. Takes the superblock lock.
*/A superblock lock? We may not have known precisely what was going on yet, but we now could perhaps see why all unmounts took such a long time: whichever call gets there first is claiming this lock while the others wait their turn.
We were able to verify this by editing our reproduction script to perform our unmounts in serial rather than in parallel. Sure enough, we saw the first unmount hang for ~8 seconds and when it was done the others, with no dirty inodes (meaning new data which has not been written to disk yet) to sync and therefore no need to hang onto that lock, completed in <0.03 seconds.
But what is the first call doing which leads it to hold a lock for, in some extreme cases, nearly 10 seconds? We can see that sync_filesystem in turn calls __sync_filesystem which, depending on the value of wait will do something with those dirty inodes. It may even take both courses of action should the first call not return < 0.
We could also see that the more mountpoints there were, or the more data was written to those mounts, the longer the sync took to flush the data: changing either the number of mounts created to 20 or the amount of data written in to 20 counts would increase the locked time to ~20 seconds.
At this point, the Garden team pulled back: we had determined the point in the kernel which was slowing down our unmounts as well as the commit which had introduced the key change. We could tell that our key commit was doing The Right Thing and that the call to sync_filesystem was necessary. The fact that the call to sync_filesystem had made the difference meant that our initial hypothesis was only partly correct: something had changed with regard to inode behaviour, but it perhaps wasn’t specific to Overlay.
Much as we would have loved to dig deeper ourselves, we are not kernel developers. Therefore we felt this was the correct point for us to return to the problems we could fix, and write this particular one up for those who had the skills to find the correct solution.
Fortunately, we have a close relationship with Canonical, so we were able to open a support ticket and get some expert help.
Our main questions were as follows:
– Could the modified ovl_sync_fs function be altered further to increase efficiency?
– Were we hitting some sort of threshold which determines when dirty inode data is synced to disk?
One last question, which had been bothering me for a while, answered itself as I began to write this blog: Why unmounts? Why did we not see this during any other Overlay operation, when there is nothing specific to unmounting about the ovl_sync_fs function? It turned out this could be seen during other Overlay operations.
While writing this, I created a new environment so that I could run my script and get some good output. To my complete and utter panic, I saw that the same script I had been reliably running through multiple kernel switches for two weeks was no longer producing the expected results. The unmounts were taking less than 0.1 of a second! I was immediately furious that I had wasted so much time being completely wrong and honestly thought I would have to start over. But when I stopped flipping my desk and actually watched the output of my script as it came through, I noticed that around the 7th mount, the output paused for a good long moment.
When I adjusted my script to create just 6 mounts, I saw what I had expected to see: slow unmounts. So the inode sync could occur during other operations in my repro script, but what was different about this new environment which had altered the behaviour? I was now even more curious to hear what Canonical had to say about my second question above.
7: The Real Culprit
Big thanks to Ioanna-Maria Alifieraki of Canonical for her work in solving the mystery! Most of this section simply paraphrases the highlights of her report.
The first thing Ioanna-Maria (Jo) told us was pretty much as we expected: the commit we found is doing The Right Thing, and any work to improve efficiency would have to be done elsewhere.
And the reason a solution would have to be found outside Overlay was because this whole thing didn’t actually have anything to do with Overlay anyway; we were just observing the effects of something else.
By watching the value of Writeback in /proc/meminfo while running the test script we provided, Jo noticed that the value remained at around zero KB while files were written to each mountpoint, but it shot up when the script came to unmounting the first point. On running the script a second time without cleaning up the directories and files created by the script, she observed this time that pages were written back during the dd of files instead; each dd hung for a visibly perceptible moment while the unmounts completed very quickly.
This was very fun for me since I had not thought to run the test script without cleaning up in between runs! And even more fun than this was that Jo observed the same writeback behaviour (none on the first dd to a file, lots on the second) without Overlay involved at all.
Jo went further: on different kernels she observed different writeback behaviour. Between 4.4 and 4.8, no writeback occurs during unmounts, which are all quick, but does occur during the dd of files. This is something I had observed during my investigation but lacked the background knowledge to make much of it. The lack of writeback during unmounts in these versions makes sense, since that call did not yet exist in the code. Interestingly, from at least 4.13 to 4.14.59 (the commit before our sync_filesystem one), no writeback occurred during either the dd or the unmount; both are very fast. Of course, this probably doesn’t mean that no pages would be written, but it does indicate that various changes have been made through the kernel versions to determine when data is synced.
Writeback happens when one of the following cases are met:
- Case 1: Free memory is below a specific threshold; flusher threads (responsible for cleaning dirty pages) write back dirty pages to disk to evict them later and free up memory.
- Case 2: Dirty data is older than a specific threshold.
- Case 3: A userspace process invokes
sync()orfsync().
Neither of our environments went anywhere near the free memory threshold, so we can ignore Case 1.
In a standard run of my repro script, while technically not running from userspace, the internal mechanisms of an Overlay unmount triggered a data sync: Case 3 from our list above.
Case 2 answers the second question I posed in our ticket, and explains why Jo saw writeback occurring at a different point during the repro script when run twice in quick succession: the data was old enough. The age of dirty data is determined by how far it is past the 30 second default threshold set in /proc/sys/vm/dirty_expire_centisecs. When flusher threads wake up they check a timestamp, based on the modtime of the inode of the file, and if this timestamp is over the threshold, then the data is written back to disk.
Interestingly, this timestamp is not reset once the data is synced, which means that once it exceeds the threshold, any further dirtying of data will immediately be picked up by the flusher threads, just as Jo observed in her experiments. (She informs me her team is looking into altering this behaviour to make more sense.)
In our separate investigations, we both saw that on kernels earlier than v4.8, writing files took significantly longer than in later versions, and that the subsequent unmounts went through very quickly. Jo happened to discover that, for reasons we don’t yet know, reading from /dev/urandom is far slower in kernels up to 4.7.10. When she edited my repro script to read from /dev/zero instead, the slow writes disappeared and the slow unmounts returned.
With this knowledge, we can now understand how, on those earlier kernels, the reads slowed the script down just enough for the timestamp to creep above the threshold, triggering a sync a few actions before the unmount, by which time there was not a lot left to do.
The question now is what Garden can do to work around this behaviour. We could force a sync now and then to take the writeback hits in smaller increments, but that is about as attractive as re-writing our entire codebase in PHP.
Another option could be to set smaller values for those tunables in /proc/sys/vm, such as dirty_expire_centisecs and dirty_writeback_centisecs, but since the effects would be system-wide and generally not positive for others’ components, this plan may be a last resort.
Fortunately, we may already have a trick up our sleeve. Something we started work on nearly 2 years previously now promises to solve more than simply the problem for which it was created.
8: The Blue Line
Let’s take another look at that graph I showed you at the start of this saga:
So far I have just been recounting the drama caused us by the purple (top) line, but now we can get to the nice, well-behaved line below it.
That line is tracking the performance of a Cloud Foundry environment almost identical to the one above, but with one key difference: in that deployment we have enabled an experimental feature called OCI Mode.
The very simple summary I wrote earlier of what happens when a developer pushes/scales their app, reflects the buildpack (non-Docker app) process in Cloud Foundry today. In normal, non-OCI mode, a container is created for the application, and then the application code is downloaded from the blobstore and streamed-in. This is done for every container/app instance, generating many dirty inodes, which is why we notice such a hit when it comes to a filesystem sync.
But before we knew about the whole inode situation, OCI mode was devised to increase performance of container creates in general, by getting rid of the download and stream parts altogether. (Well almost; we still have to download once.) By combining the app code with the standard, one-size-fits-all, base root filesystem tar, we create a custom rootfs image. The resulting image tar is passed to GrootFS (our image plugin) which will return the location of an Overlay mounted hierarchy, ready for Runc to pivot_root to as it starts the container. This same custom rootfs image is used for every container, so whether a developer asks for 1 instance or 100, their code is downloaded only once, and no new files are written.
Of course, should that app be writing a whole load of files then this doesn’t save us much. But in reality the platform sees very few apps which behave like this: the very great majority will be writing to their associated database services, if at all.
Sadly, the OCI feature has been stuck for sometime as all the components of Cloud Foundry align, but we will have to wait only a little longer to find out if, when battle tested on a high volume system, it helps us mitigate the slowness introduced by the changes in inode writeback behaviour.
Until then, this means we have to find a way to live with the slowdown in our regular, non-OCI, environments, and we are very grateful to Canonical for their help.
———————————-
And that’s the end of our story! Please check out our open source tracker to see all the nitty gritty of our investigation and the one by Canonical.
All of our code is open source as well as our backlog! (Details of OCI mode development can be found by searching for the ‘oci-phase-one’ tag.)
The Garden team is also on Cloud Foundry’s Open Source Slack, feel free to stop by for a chat 🙂
The Garden team intends to share more about other investigations which have thrilled, baffled and haunted us, so stay tuned…
Garden Engineers at time of writing: Julia Nedialkova (SAP), Tom Godkin (VMware), Georgi Sabev (SAP), Danail Branekov (SAP), Giuseppe Capizzi (VMware) and Claudia Beresford (VMware).
Product Manager: Julz Friedman (IBM).



